Abstract
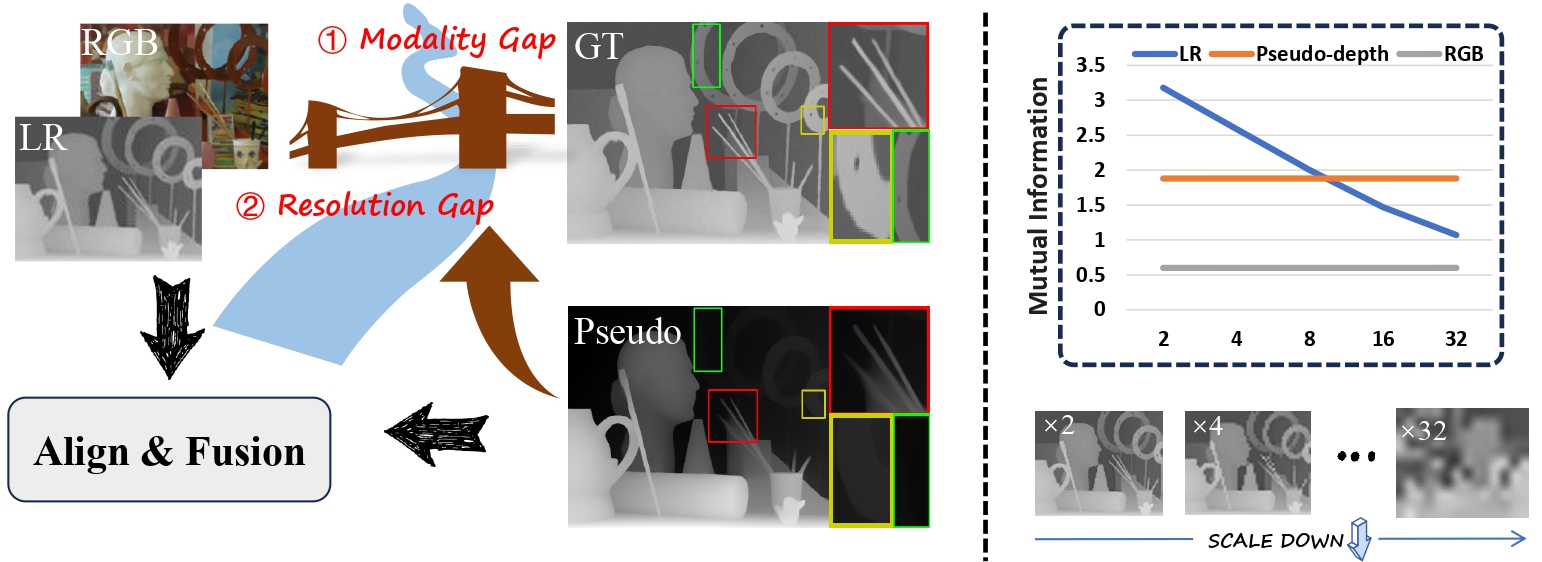
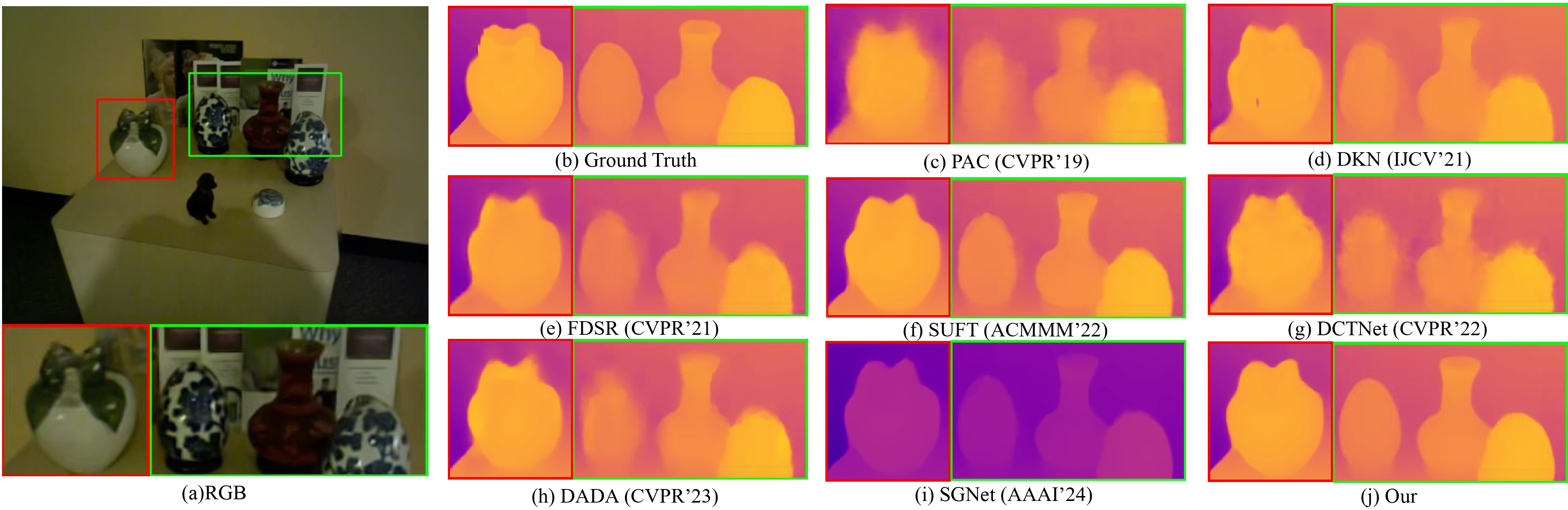
Guided Depth Super-Resolution (GDSR) presents two primary challenges: the resolution gap between Low-Resolution (LR) depth maps and High-Resolution (HR) RGB images, and the modality gap between depth and RGB data. In this study, we leverage the powerful zero-shot capabilities of large pre-trained monocular depth estimation models to address these issues. Specifically, we utilize the output of monocular depth estimation as pseudo-depth to mitigate both gaps. The pseudo-depth map is aligned with the resolution of the RGB image, offering more detailed boundary information than the LR depth map, particularly at larger scales. Furthermore, pseudo-depth provides valuable relative positional information about objects, serving as a critical scene prior to enhance edge alignment and reduce texture overtransfer. However, effectively bridging the cross-modal differences between the guidance inputs (RGB and pseudo-depth) and LR depth remains a significant challenge. To tackle this, we analyze the modality gap from three key perspectives: distribution misalignment, geometrical misalignment, and texture inconsistency. Based on these insights, we propose an alignment-then-fusion strategy, introducing a novel and efficient Dynamic Dual-Aligned and Aggregation Network (D2A2). By leveraging large pre-trained monocular depth estimation models, our approach achieves state-of-the-art performance on multiple benchmark datasets, excelling particularly in the challenging ×16 GDSR task.